
この記事では、Linuxにおける「プロセス」という概念を、基礎の基礎から、カーネルの内部動作まで段階的に解説します。コマンドを実際に動かしながら、目で見て、手で確かめながら理解を深めていきましょう
プログラムとプロセスは何が違うのか
まずは言葉の整理から
「プログラム」「プロセス」「スレッド」という言葉は、なんとなく同じ意味で使われがちです。しかし Linux の世界では、この3つは明確に異なる概念です。ここをしっかり区別することが、この先の理解の土台になります。
プログラムとは
プログラムとは、ディスク(ストレージ)の上にある静的なファイルのことです。
$ ls -la /usr/bin/bash
-rwxr-xr-x 1 root root 1396520 /usr/bin/bash/usr/bin/bash というファイルがプログラムです。それ自体は何もしません。ただそこに存在しているだけです。料理のレシピ本に例えると、本棚に置かれたレシピ本です。
プロセスとは
プロセスとは、プログラムをメモリにロードして、実際に実行している「生きている状態」のことです。OSが管理するリソース(資源)の単位でもあります。
先ほどのレシピ本の例で言えば、調理台でシェフが実際に料理を作っている状態です。同じレシピ本(プログラム)から、複数の料理(プロセス)を同時に作ることもできます。
# 同じbashプログラムから複数のプロセスが起動している例
$ ps aux | grep bash
hirotano 4250 0.0 bash # SSH接続1つ目のbash
hirotano 4163 0.0 bash # GNOMEターミナルのbashスレッドとは
スレッドとは、1つのプロセスの中にある「実行の流れ」のことです。1つのプロセスの中に複数のスレッドを持つことができ、それらは同じメモリ空間を共有しながら並行して動作します。
プログラム(/usr/bin/bash)
│
│ 実行される
▼
プロセス(メモリ・PID・FDを持つ)
│
│ 必要に応じて
▼
スレッド(同じプロセス内で並行実行)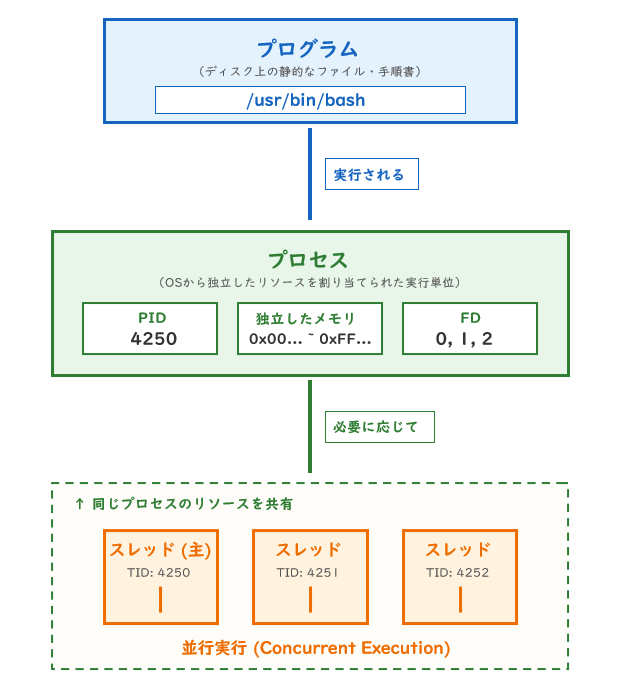
3つの違いをまとめると
| 概念 | 場所 | 状態 | 単位 |
|---|---|---|---|
| プログラム | ディスク上 | 静的(動かない) | ファイル |
| プロセス | メモリ上 | 動的(実行中) | リソース管理の単位 |
| スレッド | プロセス内 | 動的(並行実行) | CPU実行の単位 |
プロセスのライフサイクル
プロセスは「生まれて、動いて、死ぬ」というサイクルを持っています。Linuxカーネルはプロセスが今どの状態にあるかを常に把握して管理しています。
プロセスの5つの状態
flowchart TD
ST["● 開始"] -->|"プログラム実行"| A["New(生成中) OSがメモリを確保"]
A -->|"メモリ割り当て完了"| B["Ready(実行可能) CPU待ち状態"]
B -->|"CPUのスケジューリング"| C["Running(実行中) CPUで命令を処理"]
C -->|"タイムスライス切れ"| B
C -->|"I/O待ち・sleep等"| D["Waiting(待機中) I/O完了を待つ"]
D -->|"I/O完了・イベント発生"| B
C -->|"exit()呼び出し"| E["Terminated(終了) 管理情報のみ残る"]
E -->|"親がwait()で回収"| END["● 消滅"]
classDef default fill:#BBD4F0,stroke:#1F4E79,stroke-width:1.5px,color:#0B2545
classDef decision fill:#FFE699,stroke:#806000,stroke-width:1.5px,color:#0B2545各状態の意味を丁寧に見ていきましょう。
New(生成中)
プロセスが生まれようとしている瞬間です。OSがメモリを確保して、プロセスの管理情報を作成しています。
Ready(実行可能)
実行の準備は完了しているが、CPUが空くのを待っている状態です。「CPUを使いたいけど、今は順番待ち」というイメージです。
Running(実行中)
実際にCPUで命令が処理されている状態です。CPUが1つしかなければ、Running状態のプロセスは同時に1つだけです。
Waiting(待機中)
ディスクの読み書きや、ネットワーク通信の完了を待っている状態です。この間、CPUは他のプロセスのために解放されます。
ポイント: Waiting にはさらに2種類あります。
S(Interruptible Sleep):割り込み可能な待機。通常のI/O待ち。シグナルで起こせる。D(Uninterruptible Sleep):割り込み不可の待機。ディスクI/Oの完了待ち。kill -9でも殺せない。
Terminated(終了)
プロセスがexit()を呼び出して終了した状態です。しかし、親プロセスがwait()で終了を回収するまで、プロセスの管理情報だけが残り続けます(ゾンビプロセス)。
実際の状態を確認してみる
# 全プロセスの状態を確認(STAT列に注目)
ps aux
# 出力例
USER PID %CPU %MEM VSZ RSS TTY STAT CMD
hirotano 4250 0.0 0.0 6704 5392 pts/1 Ss -bash
root 1 0.0 0.0 168368 11780 ? Ss /sbin/initSTAT列の読み方:
| 記号 | 意味 |
|---|---|
R | Running(実行中・実行可能) |
S | Sleeping(割り込み可能な待機) |
D | Disk Sleep(割り込み不可の待機) |
Z | Zombie(終了済みだが未回収) |
T | Stopped(Ctrl+Zで一時停止) |
s | セッションリーダー |
+ | フォアグラウンドプロセス |
ユーザ空間とカーネル空間
CPUには「特権レベル」がある
CPUはすべての命令を同じ権限で実行しているわけではありません。Intel/AMDのx86アーキテクチャでは、Ring 0〜Ring 3という特権レベルが定義されています。
Linuxはこのうち2つを使います。
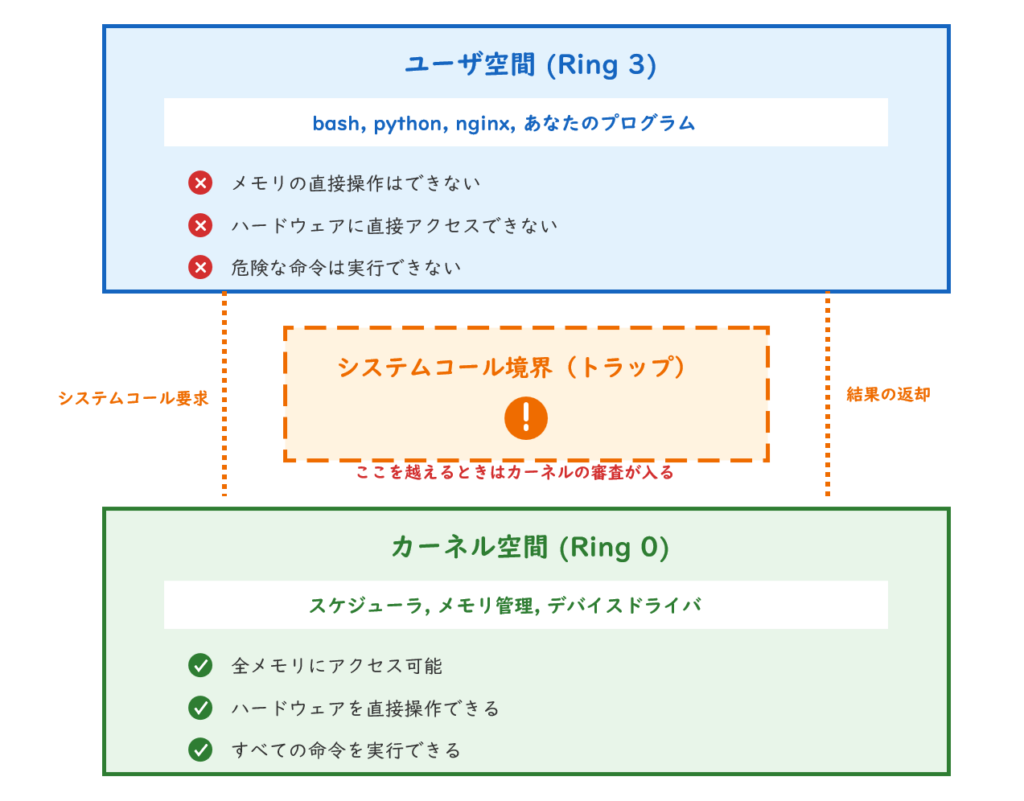
なぜ2つに分けるのか
もしすべてのプログラムがRing 0(特権モード)で動いていたら、悪意あるプログラムやバグのあるプログラムが、OS全体や他のプロセスのメモリを破壊できてしまいます。
ユーザ空間で動くプログラムを制限することで、OSと他のプロセスを保護しているわけです。
システムコール — 2つの世界をつなぐ橋
ユーザ空間のプログラムがファイルを読みたい、画面に出力したいと思ったとき、カーネルに「お願い」をする必要があります。この「お願い」の仕組みがシステムコールです。
sequenceDiagram
participant App as アプリ(ユーザ空間)
participant Kernel as カーネル(カーネル空間)
participant HW as ハードウェア
App->>Kernel: read() システムコール発行
Note over App,Kernel: Ring3 → Ring0 へモード切り替え
Kernel->>HW: ディスクにI/O要求
HW-->>Kernel: データ返却
Kernel-->>App: データをユーザ空間にコピー
Note over App,Kernel: Ring0 → Ring3 へ戻るstraceコマンドを使うと、プログラムが発行するシステムコールをすべて観察できます。
# lsコマンドが発行するシステムコールを追う
strace ls 2>&1 | head -30
# 出力例(抜粋)
execve("/usr/bin/ls", ["ls"], 0x... /* 環境変数 */) = 0
openat(AT_FDCWD, "/etc/ld.so.cache", O_RDONLY|O_CLOEXEC) = 3
read(3, "\177ELF\2\1\1\0\0..."..., 832) = 832
write(1, "file1 file2 file3\n", 20) = 20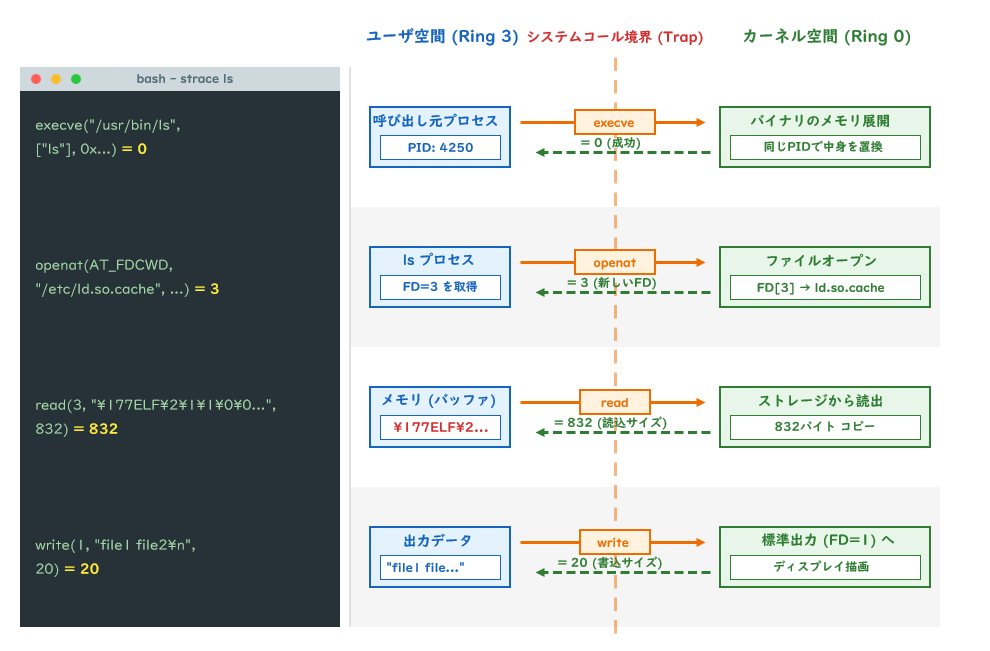
lsという単純なコマンドでも、内部では何十ものシステムコールが呼ばれています。
procファイルシステム
/proc とは何か
/procディレクトリは、ディスク上に実在するディレクトリではありません。Linuxカーネルがメモリ上に作り出した仮想的なファイルシステムです。
カーネルが管理しているプロセスの情報を、ファイルとして読み取れる形で見せてくれています。/proc/[PID]/というディレクトリが、各プロセスの「管理情報の窓口」になっています。
# bashのPIDを確認
$ echo $$
4250
# そのプロセスの/procディレクトリを見る
$ ls /proc/4250/
arch_status cmdline environ fd maps mem status ...task_struct — カーネルがプロセスを管理する構造体
Linuxカーネルの内部では、各プロセスの情報を task_struct という C言語の構造体で管理しています。/proc/[PID]/status はその中身を人間が読める形で表示したものです。
$ cat /proc/4250/status実際の出力と、各フィールドの意味:
Name: bash # プロセス名
State: S (sleeping) # 現在の状態(入力待ち)
Pid: 4250 # このプロセスのID
PPid: 4249 # 親プロセスのID(sshdプロセス)
Threads: 1 # スレッド数(bashはシングルスレッド)
VmSize: 6704 kB # 仮想アドレス空間の合計
VmRSS: 5392 kB # 実際に物理RAMに乗っている量
voluntary_ctxt_switches: 106 # 自らCPUを手放した回数
nonvoluntary_ctxt_switches: 192 # OSに強制的に切り替えられた回数VmSize と VmRSS の違いが重要
この2つは混同しやすいポイントです。
| 項目 | 意味 |
|---|---|
VmSize(仮想メモリサイズ) | OSに「使うかもしれない」と予約した領域の合計 |
VmRSS(物理メモリサイズ) | 実際に物理RAMに乗っている量 |
VmSize > VmRSS なのが正常です。Linuxは**「必要になるまで物理メモリを割り当てない(遅延割り当て)」**という設計になっているため、予約だけして実体がないページが存在します。
プロセスツリー — 全プロセスは家族
すべてのプロセスは「親子関係」を持っています。pstreeコマンドで確認してみましょう。
$ pstree -p
systemd(1)─┬─sshd(1262)───sshd(4176)───sshd(4249)───bash(4250)───pstree(6870)
├─NetworkManager(646)
...SSHでログインしてコマンドを打つまでの流れがそのまま見えています。
flowchart TD
A["systemd(PID 1) 全プロセスの祖先"] --> B["sshd(PID 1262) SSHサーバ本体(常駐)"]
B --> C["sshd(PID 4176) 接続を受け付けた子"]
C --> D["sshd(PID 4249) 認証・セッション管理"]
D --> E["bash(PID 4250) あなたのログインシェル"]
E --> F["pstree(PID 6870) 実行したコマンド"]
classDef default fill:#BBD4F0,stroke:#1F4E79,stroke-width:1.5px,color:#0B2545
classDef decision fill:#FFE699,stroke:#806000,stroke-width:1.5px,color:#0B2545コマンドを打つたびに bash が子プロセスを生み出し、コマンドが終わると消えます。これが次章で解説する fork-exec の実例です。
/proc/[PID]/maps — メモリマップを覗く
$ cat /proc/4250/maps出力を整理すると、プロセスの仮想アドレス空間の全体像が見えます。
アドレス範囲 権限 内容
622bd09f4000-622bd0b55000 r-xp /usr/bin/bash ← コード(命令列)
622bd0b55000-622bd0b60000 rw-p /usr/bin/bash ← データ領域
622c062cc000-622c06416000 rw-p [heap] ← ヒープ(動的確保)
74d607800000-74d607a05000 r-xp libc.so.6 ← 標準Cライブラリ
7fffb6184000-7fffb61a5000 rw-p [stack] ← スタックこれをアドレス空間のレイアウトとして図示すると:
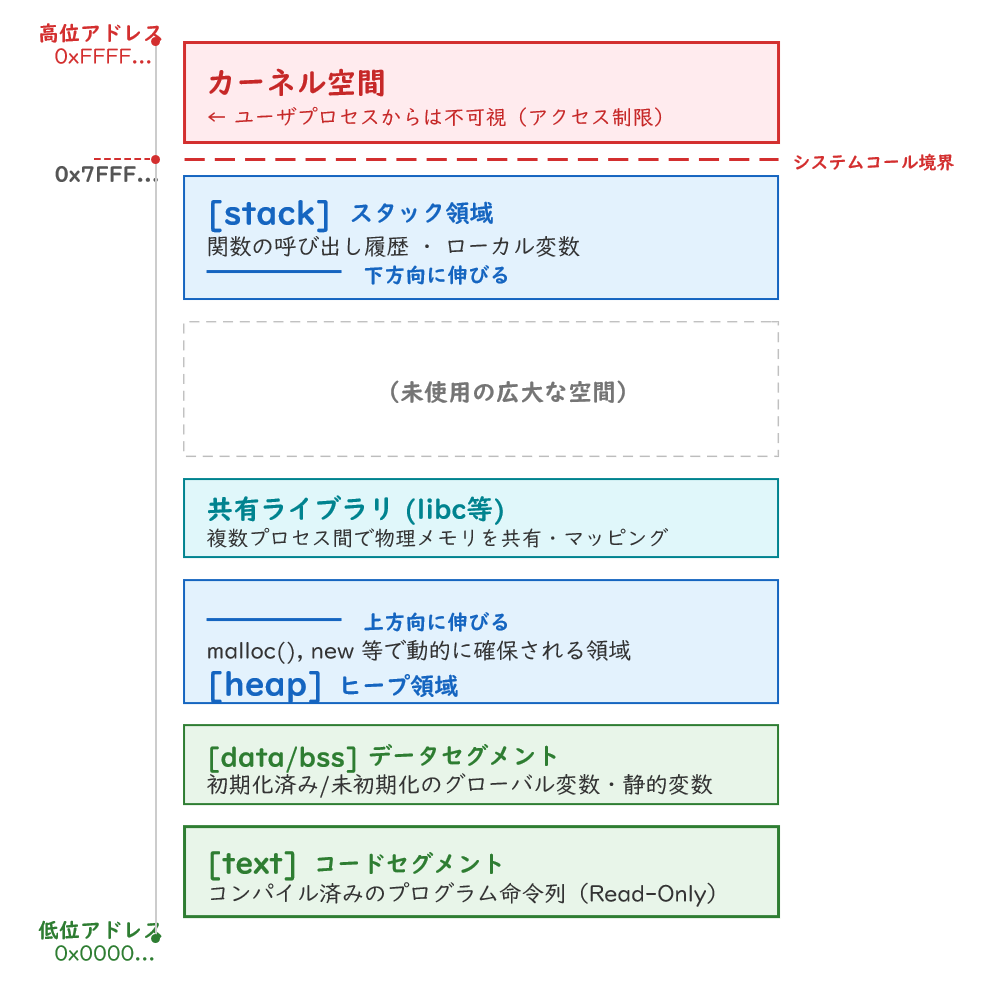
ファイルディスクリプタ
「プロセスの口」という概念
プロセスはファイルを読んだり、画面に出力したり、ネットワーク通信をしたりします。これらの「何かと繋がっている口」を管理するために、Linuxはファイルディスクリプタ(fd)という仕組みを使っています。
一言で言えば、「プロセスが何かに繋がっている口に付けた番号」です。
重要な設計思想: Linuxは「すべてをファイルとして扱う」という哲学を持っています。通常のファイルだけでなく、端末、パイプ、ソケット、デバイスも、すべてfdという同じ仕組みで扱えます。
ファイルディスクリプタの3層構造
fdは単なる整数番号ですが、その裏側にはカーネルが管理する実体があります。
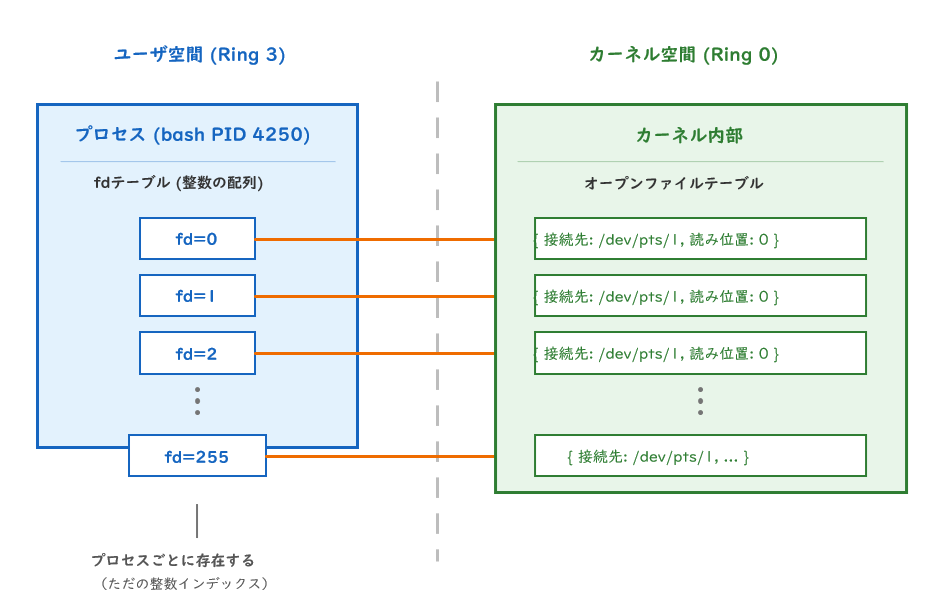
fdはプロセス内だけで有効な番号です。「どのファイルに繋がっているか」「どこまで読んだか」という実体はカーネル側が管理しています。
0, 1, 2 は予約済みの特別な番号
Unix誕生のころからの約束事で、すべてのプロセスは起動時に必ずこの3つのfdを持っています。
| fd番号 | 名前 | 役割 |
|---|---|---|
| 0 | stdin(標準入力) | キーボードからの入力など |
| 1 | stdout(標準出力) | 通常の出力先(画面など) |
| 2 | stderr(標準エラー) | エラーメッセージの出力先 |
bashで確認すると:
$ ls -la /proc/$$/fd
lrwx------ 0 -> /dev/pts/1 ← stdin = SSH端末
lrwx------ 1 -> /dev/pts/1 ← stdout = SSH端末
lrwx------ 2 -> /dev/pts/1 ← stderr = SSH端末
lrwx------ 255 -> /dev/pts/1 ← bashの内部制御用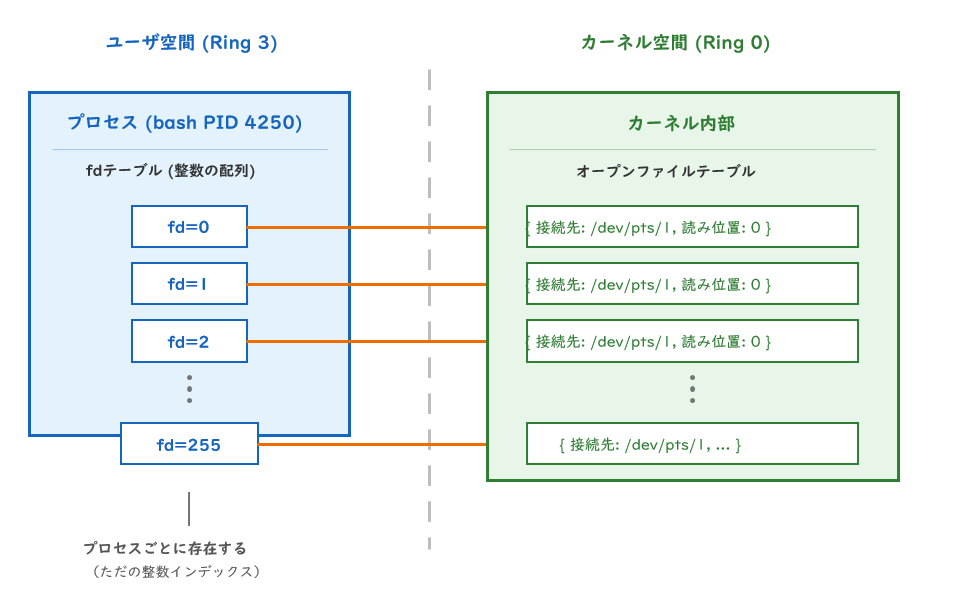
画面に文字が表示されるのは、printfがfd=1に書き込み、それがSSH端末(/dev/pts/1)に繋がっているからです。
実際にfdの増減を観察する
# ファイルを開いてfdが増えるか確認
exec 3< /etc/hostname # fd=3 で /etc/hostname を開く
ls -la /proc/$$/fd # fd=3 が追加されているはず
cat <&3 # fd=3 から読む
exec 3<&- # fd=3 を閉じる
ls -la /proc/$$/fd # fd=3 が消えているはず実際の結果:
# exec 3< /etc/hostname 後
lr-x------ 3 -> /etc/hostname ← 追加された!読み取り専用(r)
# cat <&3 の結果
Ubuntu-1 ← /etc/hostname の中身が読めた
# exec 3<&- 後
fd=3 が消えた ← 解放完了この実験で確認できたこと:
| 操作 | 確認できた概念 |
|---|---|
| fd=3 が出現 | 最小番号ルール(0,1,2,255の次は3) |
lr-x パーミッション | 開き方(読み/書き)がカーネルに記録される |
cat <&3 で読めた | fdは「口の番号」で中身はカーネルが管理 |
| fd=3 が消えた | closeによるリソース解放 |
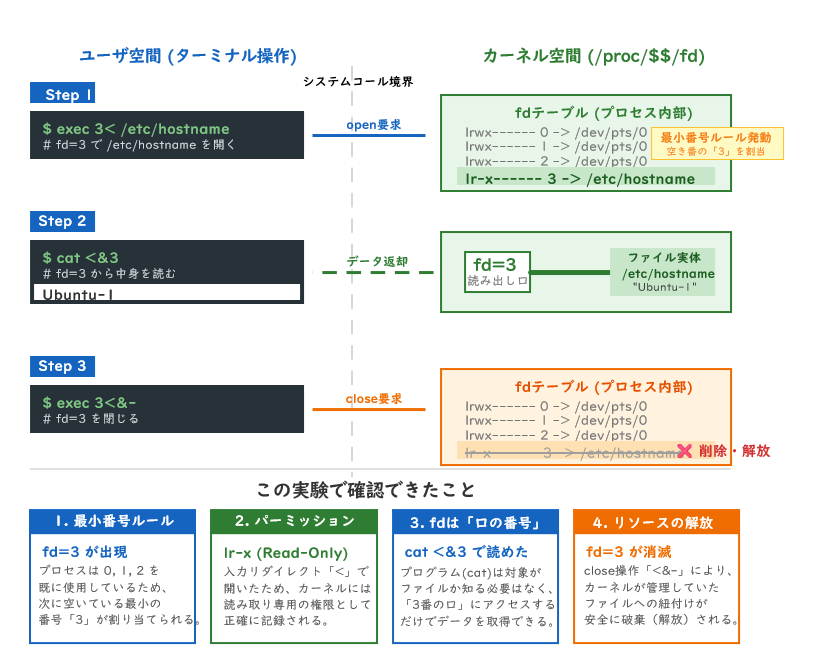
「最小番号ルール」がリダイレクトを実現する
Linuxには「新しいfdには、空いている最小の番号を割り当てる」というルールがあります。このルールを使って、bashはリダイレクト(>)を実現しています。
ls > output.txt が実行されるとき、bashの子プロセス内部でこんなことが起きています:
flowchart TD
A["子プロセス起動直後 fd=0,1,2 → /dev/pts/1(端末)"] --> B["close(fd=1) stdout を閉じる"]
B --> C["fd=1 が空きになる"]
C --> D["open('output.txt') ファイルを開く"]
D --> E["最小番号ルール適用 空き最小番号 = fd=1 を割り当て"]
E --> F["fd=1 → output.txt\nstdout がファイルに差し替わった"]
F --> G["exec('/bin/ls') ls に変身"]
G --> H["ls は fd=1 に書くだけ → output.txt に書き込まれる"]
classDef default fill:#BBD4F0,stroke:#1F4E79,stroke-width:1.5px,color:#0B2545
classDef decision fill:#FFE699,stroke:#806000,stroke-width:1.5px,color:#0B2545lsのソースコードは一切変更不要です。「fd=1に書く」という動作はそのままで、繋ぎ先だけが変わっています。
パイプ ls | grep foo の仕組み
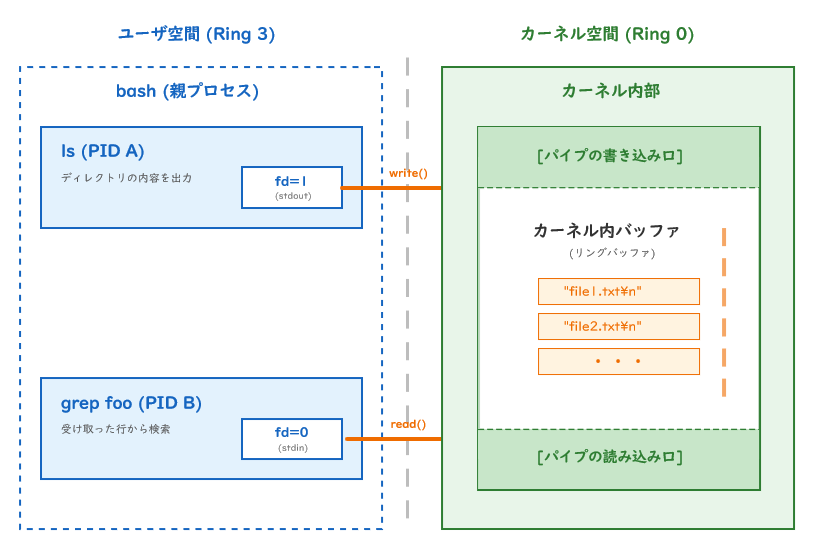
lsの stdout と grepの stdin がパイプで繋がっています。lsもgrepも「fd=1に書く」「fd=0から読む」だけで、相手が誰かを知りません。
forkとexec
プロセスはどうやって生まれるか
Linuxで新しいプロセスを作るには、fork()とexec()という2つのシステムコールを組み合わせます。
flowchart TD
A["bash が ls を実行しようとする"] --> B["fork() 呼び出し"]
B --> C["親プロセス: bash(PID 4250) wait() で子の終了を待つ"]
B --> D["子プロセス: bashのコピー(PID 6900)"]
D --> E["fdの張り替えなど 環境セットアップ"]
E --> F["exec('/bin/ls') 呼び出し"]
F --> G["子プロセスが ls に変身"]
G --> H["ls が実行される"]
H --> I["exit() で終了"]
I --> J["親が終了を検知\nbash がプロンプトを表示"]
C --> J
classDef default fill:#BBD4F0,stroke:#1F4E79,stroke-width:1.5px,color:#0B2545
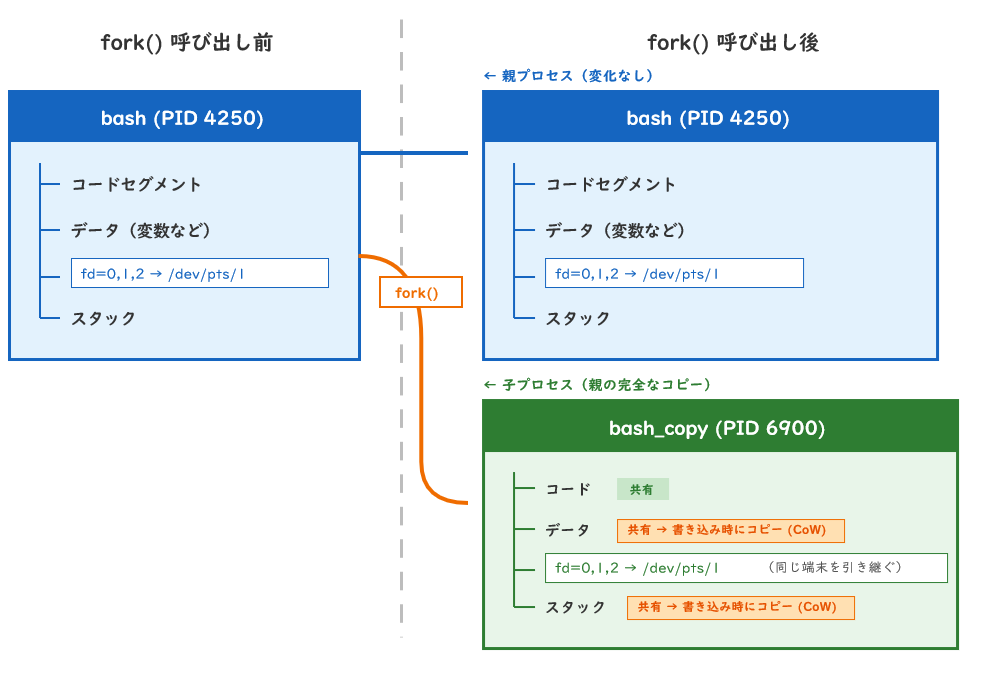
classDef decision fill:#FFE699,stroke:#806000,stroke-width:1.5px,color:#0B2545fork() — プロセスを「複製」する
fork()を呼ぶと、呼び出したプロセスの完全なコピーが作られます。
pid_t pid = fork();
if (pid < 0) {
// エラー
} else if (pid == 0) {
// ここは子プロセスだけが通る(forkの戻り値が0)
printf("私は子プロセス。PID=%d\n", getpid());
} else {
// ここは親プロセスだけが通る(forkの戻り値が子のPID)
printf("私は親プロセス。子のPID=%d\n", pid);
}fork後の状態:
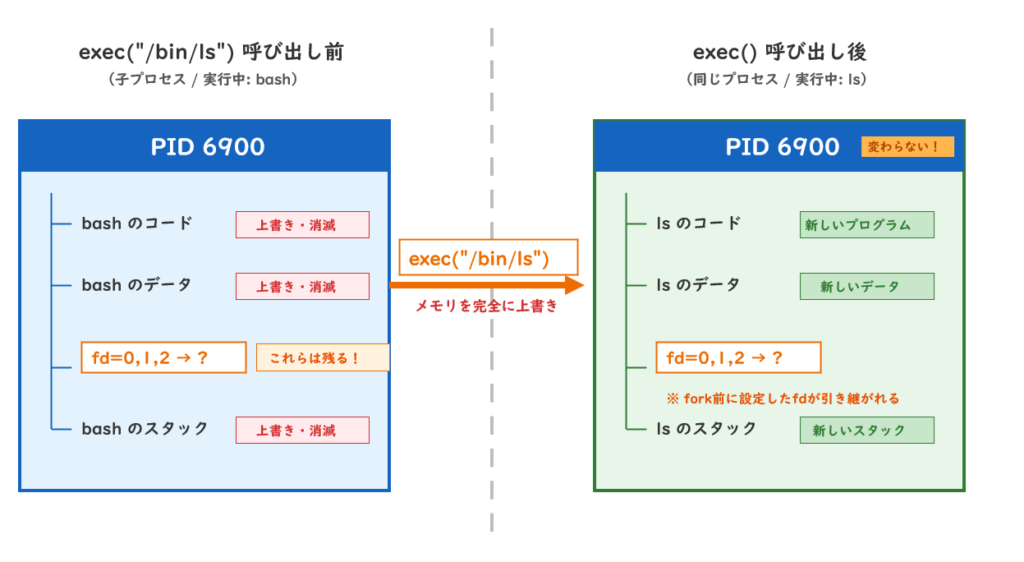
exec() — プロセスを「別のプログラムに置き換える」
exec()を呼ぶと、現在のプロセスのメモリ(コード・データ・スタック)が、指定したプログラムの内容で完全に上書きされます。
重要:
exec()を呼んでもPIDは変わりません。中身だけが置き換わります。
なぜforkとexecは分かれているのか
これはUnixの設計で最もエレガントな部分の一つです。もしforkexec()という一つの関数しかなかったとしたら、子プロセスが実行を始める前に介入する余地がありません。
fork()とexec()の間のわずかな時間に、子プロセスは自分の環境を自由にセットアップできます。
| fork後・exec前にできること | 用途 |
|---|---|
| ファイルディスクリプタの張り替え | ls > file.txt などのリダイレクト |
| パイプの接続 | ls | grep foo などのパイプライン |
| 環境変数の変更 | 実行環境の調整 |
| nice値の変更 | 優先度を下げてから実行 |
| シグナルマスクの設定 | 特定シグナルの制御 |
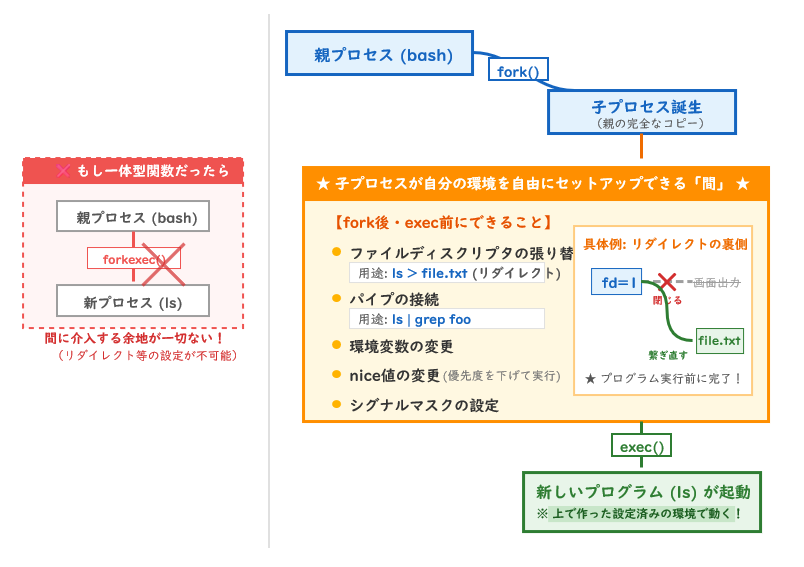
分離されているから、この「間」が存在します。これがUnixの設計思想「一つのことをうまくやれ(Do one thing well)」のシステムコールレベルでの体現です。
pstreeで見たSSHログインの経路が示すもの
systemd(1)
└─sshd(1262)
└─sshd(4176)
└─sshd(4249)
└─bash(4250) ← あなたのシェル
└─pstree(6870)この木構造は、すべてfork-execの連鎖でできています。
flowchart TD
A["systemd 全プロセスの祖先"] -->|"fork() + exec(sshd) で起動"| B["sshd(PID 1262) 接続を待ち受け"]
B -->|"SSH接続が来たら fork()"| C["sshd(PID 4176) 接続受付の子プロセス"]
C -->|"fork() + exec(sshd)"| D["sshd(PID 4249) 認証・セッション管理"]
D -->|"fork() + exec(bash)"| E["bash(PID 4250) あなたのログインシェル完成"]
classDef default fill:#BBD4F0,stroke:#1F4E79,stroke-width:1.5px,color:#0B2545
classDef decision fill:#FFE699,stroke:#806000,stroke-width:1.5px,color:#0B2545Copy-on-Write
forkは「コピー」しているのか?
fork()はプロセスの完全なコピーを作ると説明しました。しかし、bashのように数十MBのメモリを使っているプロセスを毎回フルコピーしていたら、パフォーマンスが大変なことになります。
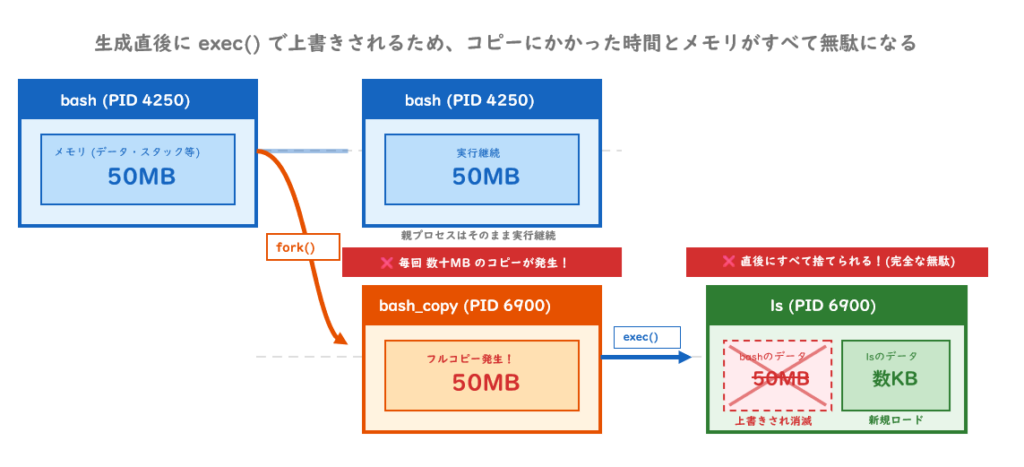
Linuxはこの問題をCopy-on-Write(CoW)という仕組みで解決しています。
CoWの基本原理:「書くまでは共有する」
flowchart TD
subgraph BEFORE["fork() 直後"]
P1["親プロセスの仮想アドレス空間"] --> PM["物理メモリ(実体) 変数の値: 100"]
C1["子プロセスの仮想アドレス空間"] --> PM
NOTE1["同じ物理メモリを指している コピーコスト: ゼロ"]
end
subgraph AFTER["子が書き込んだ後"]
P2["親プロセスの仮想アドレス空間"] --> PM2["物理メモリA(元のページ) 変数の値: 100"]
C2["子プロセスの仮想アドレス空間"] --> PM3["物理メモリB(コピーされた新ページ) 変数の値: 999"]
NOTE2["書き込みが発生したページだけコピー 他のページは引き続き共有"]
end
BEFORE -->|"子プロセスが変数に書き込む CoW発動!"| AFTER
classDef default fill:#BBD4F0,stroke:#1F4E79,stroke-width:1.5px,color:#0B2545
classDef decision fill:#FFE699,stroke:#806000,stroke-width:1.5px,color:#0B2545CoWが発動するメカニズム(ステップ詳解)
CoWはカーネルとCPUが協調して動作します。
flowchart TD
A["子プロセス 変数に書き込もうとする"] --> B["CPU(MMU) ページテーブルを確認"]
B --> C{"このページは書き込み禁止フラグが立っている"}
C -->|"書き込み禁止を検出"| D["ページフォルト発生 カーネルへ割り込み"]
D --> E["カーネル 該当ページを物理メモリにコピー"]
E --> F["カーネル 子のページテーブルをコピー先に更新"]
F --> G["書き込み禁止フラグを解除"]
G --> H["書き込みを再実行 今度は成功!"]
classDef default fill:#BBD4F0,stroke:#1F4E79,stroke-width:1.5px,color:#0B2545
classDef decision fill:#FFE699,stroke:#806000,stroke-width:1.5px,color:#0B2545
class C decision実際にCコードで確認する
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
#include <sys/wait.h>
int global_var = 100; // 親子で共有されるデータ
int main() {
printf("=== fork前 ===\n");
printf("親: global_var = %d, アドレス = %p\n", global_var, &global_var);
pid_t pid = fork();
if (pid == 0) {
// 子プロセス:書き込み前
printf("\n=== 子プロセス(書き込み前) ===\n");
printf("子: global_var = %d, アドレス = %p\n", global_var, &global_var);
// 書き込み → ここでCoWが発動!
global_var = 999;
printf("\n=== 子プロセス(書き込み後) ===\n");
printf("子: global_var = %d, アドレス = %p\n", global_var, &global_var);
exit(0);
} else {
wait(NULL);
printf("\n=== 親プロセス(子の終了後) ===\n");
printf("親: global_var = %d, アドレス = %p\n", global_var, &global_var);
}
return 0;
}$ gcc -o cow_demo cow_demo.c && ./cow_demo実際の実行結果:
=== fork前 ===
親: global_var = 100, アドレス = 0x5729856bd010
=== 子プロセス(書き込み前) ===
子: global_var = 100, アドレス = 0x5729856bd010
=== 子プロセス(書き込み後) ===
子: global_var = 999, アドレス = 0x5729856bd010 ← 値は変わった
=== 親プロセス(子の終了後) ===
親: global_var = 100, アドレス = 0x5729856bd010 ← 親は影響ゼロ!この結果が示すこと
4行すべてで仮想アドレスが 0x5729856bd010 と同じです。しかし値は独立しています。
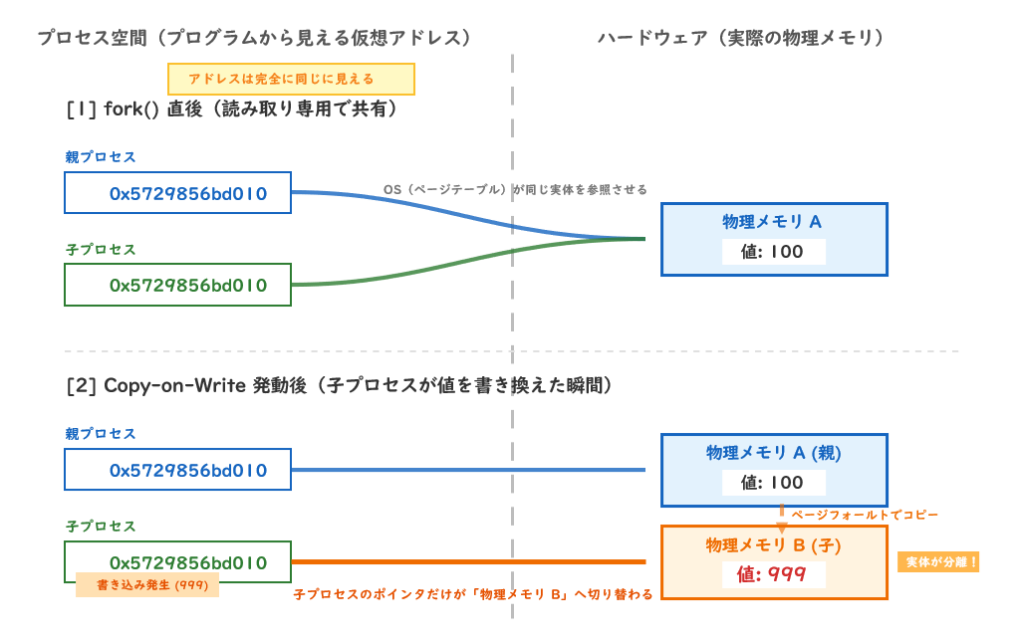
「同じ仮想アドレスなのに値が違う」のはなぜ矛盾しないのか:
仮想アドレスはプロセスごとに独立した「番地の体系」です。現実の住所で例えると:
東京都A区1丁目1番地 → 実際の土地A(親が持つ)
大阪府B区1丁目1番地 → 実際の土地B(子が持つ)
「1丁目1番地」という表記は同じでも、
都市(プロセス)が違えば別の場所を指すCoWとfork-execの組み合わせが最強な理由
fork-execパターンでは、CoWのおかげでコピーコストがほぼゼロになります。「新しいプロセスを作るコストが極めて低い」というのがUnix/Linuxの強みの一つであり、これがシェルでコマンドをどんどん実行できる理由でもあります。
まとめ
この記事で学んだことを整理します。
各概念の繋がり
| 概念 | 実験・確認方法 | 理解のポイント |
|---|---|---|
| プロセスの実体 | cat /proc/$$/status | task_structの中身が見える |
| メモリレイアウト | cat /proc/$$/maps | 仮想アドレス空間の全体像 |
| ファイルディスクリプタ | ls -la /proc/$$/fd | プロセスの「口」が見える |
| fork-exec | pstree -p | 全プロセスの親子関係 |
| Copy-on-Write | Cコードのアドレス比較 | 同じ仮想アドレス・別の物理実体 |
コメント